

python第二轮学习
对前面的基础进行跟更加精细的讲解,对内容进行补充讲解以及拓展!
列表推导式和字典推导式
在 Python 中推导式是一种非常 Pythonic 的知识,本篇文章将为你详细解答列表推导式与字典推导式相关的技术知识。
列表推导式
列表推导式可以利用列表,元组,字典,集合等数据类型,快速的生成一个特定需要的列表。
语法格式如下:
[表达式 for 迭代变量 in 可迭代对象 [if 条件表达式]]if 条件表达式 非必选,学完列表推导式之后,你可以发现它就是 for 循环的一个变种语句,例如咱们现有一个需求是将一个列表中的所有元素都变成原值的 2 倍。
for 循环写法
♾️ python 代码:my_list = [1,2,3]
new_list = []
for i in my_list:
new_list.append(i*2)
print(new_list)
列表推导式写法
♾️ python 代码:nn_list = [i*2 for i in my_list]
print(nn_list)是不是对比看就是将 for 循环语句做了变形之后,增加了一个 [],不过需要注意的是,列表推导式最终会将得到的各个结果组成一个新的列表。
再看一下列表推导式语法构成 nn_list = [i*2 for i in my_list] ,for 关键字后面就是一个普通的循环,前面的表达式 i*2 其中的 i 就是 for 循环中的变量,也就是说表达式可以用后面 for 循环迭代产生的变量,理解这个内容列表推导式就已经掌握 9 成内容了,剩下的是熟练度的问题。
在将 if 语句包含进代码中,运行之后,你也能掌握基本技巧,if 语句是一个判断,其中 i 也是前面循环产生的迭代变量。
♾️ python 代码:nn_list = [i*2 for i in my_list if i>1]
print(nn_list)这些都是一般技能,列表推导式能支持两层 for 循环,例如下述代码:
nn_list = [(x,y) for x in range(3) for y in range(3) ]
print(nn_list)当然如果你想加密(谁都看不懂你的代码)你的代码,你可以无限套娃下去,列表推导式并没有限制循环层数,多层循环就是一层一层的嵌套,你可以展开一个三层的列表推导式,就都明白了
♾️ python 代码:nn_list = [(x,y,z,m) for x in range(3) for y in range(3) for z in range(3) for m in range(3)]
print(nn_list)当然在多层列表推导式里面,依旧支持 if 语句,并且 if 后面可以用前面所有迭代产生的变量,不过不建议超过 2 成,超过之后会大幅度降低你代码的可阅读性。
当然如果你希望你代码更加难读,下面的写法都是正确的。
♾️ python 代码:nn_list = [(x, y, z, m) for x in range(3) if x > 1 for y in range(3) if y > 1 for z in range(3) for m in range(3)]
print(nn_list)
nn_list = [(x, y, z, m) for x in range(3) for y in range(3) for z in range(3) for m in range(3) if x > 1 and y > 1]
print(nn_list)
nn_list = [(x, y, z, m) for x in range(3) for y in range(3) for z in range(3) for m in range(3) if x > 1 if y > 1]
print(nn_list)现在你已经对列表推导式有比较直观的概念了,列表推导式对应的英文是 list comprehension,有的地方写作列表解析式,基于它最后的结果,它是一种创建列表的语法,并且是很简洁的语法。
有了两种不同的写法,那咱们必须要对比一下效率,经测试小数据范围影响不大,当循环次数到千万级时候,出现了一些差异。
♾️ python 代码:import time
def demo1():
new_list = []
for i in range(10000000):
new_list.append(i*2)
def demo2():
new_list = [i*2 for i in range(10000000)]
s_time = time.perf_counter()
demo2()
e_time = time.perf_counter()
print("代码运行时间:", e_time-s_time)
运行结果:
♾️ python 代码:# for 循环
代码运行时间: 1.3431036140000001
# 列表推导式
代码运行时间: 0.9749278849999999在 Python3 中列表推导式具备局部作用域,表达式内部的变量和赋值只在局部起作用,表达式的上下文里的同名变量还可以被正常引用,局部变量并不会影响到它们。所以其不会有变量泄漏的问题。例如下述代码:
x = 6
my_var = [x*2 for x in range(3)]
print(my_var)
print(x)列表推导式还支持嵌套
参考代码如下,只有想不到,没有做不到的。
my_var = [y*4 for y in [x*2 for x in range(3)]]
print(my_var)字典推导式
有了列表推导式的概念,字典推导式学起来就非常简单了,语法格式如下:
{键:值 for 迭代变量 in 可迭代对象 [if 条件表达式]}直接看案例即可
♾️ python 代码:my_dict = {key: value for key in range(3) for value in range(2)}
print(my_dict)得到的结果如下:
♾️ python 代码:{0: 1, 1: 1, 2: 1}此时需要注意的是字典中不能出现同名的 key,第二次出现就把第一个值覆盖掉了,所以得到的 value 都是 1。
最常见的哪里还是下述的代码,遍历一个具有键值关系的可迭代对象。
♾️ python 代码:my_tuple_list = [('name', '酒笙'), ('age', 18),('class', 'no1'), ('like', 'python')]
my_dict = {key: value for key, value in my_tuple_list}
print(my_dict)元组推导式与集合推导式
其实你应该能猜到,在 Python 中是具备这两种推导式的,而且语法相信你已经掌握了。不过语法虽然差不多,但是元组推导式运行结果却不同,具体如下。
my_tuple = (i for i in range(10))
print(my_tuple)运行之后产生的结果:
♾️ python 代码:<generator object <genexpr> at 0x0000000001DE45E8>使用元组推导式生成的结果并不是一个元组,而是一个生成器对象,需要特别注意下,这种写法在有的地方会把它叫做生成器语法,不叫做元组推导式。
集合推导式也有一个需要注意的地方,先看代码:
♾️ python 代码:my_set = {value for value in 'HelloWorld'}
print(my_set)因为集合是无序且不重复的,所以会自动去掉重复的元素,并且每次运行显示的顺序不一样,使用的时候很容易晕掉。
字典和集合
字典和集合那些基础操作
先说字典
字典是由键值对组成的,键为 Key,值为 Value,标记一下,在 Python3.6 之前字典是无需的,长度大小可变,元素也可以任意的删除和改变,在 Python 3.7 之后,字典有序了。
为了测试字典的无序性,我专门在 Python 线上环境进行了测试,代码如下:
♾️ python 代码:my_dict = {}
my_dict["A"] = "A"
my_dict["B"] = "B"
my_dict["C"] = "C"
my_dict["D"] = "D"
for key in my_dict:
print(key)运行结果也证明了无序性。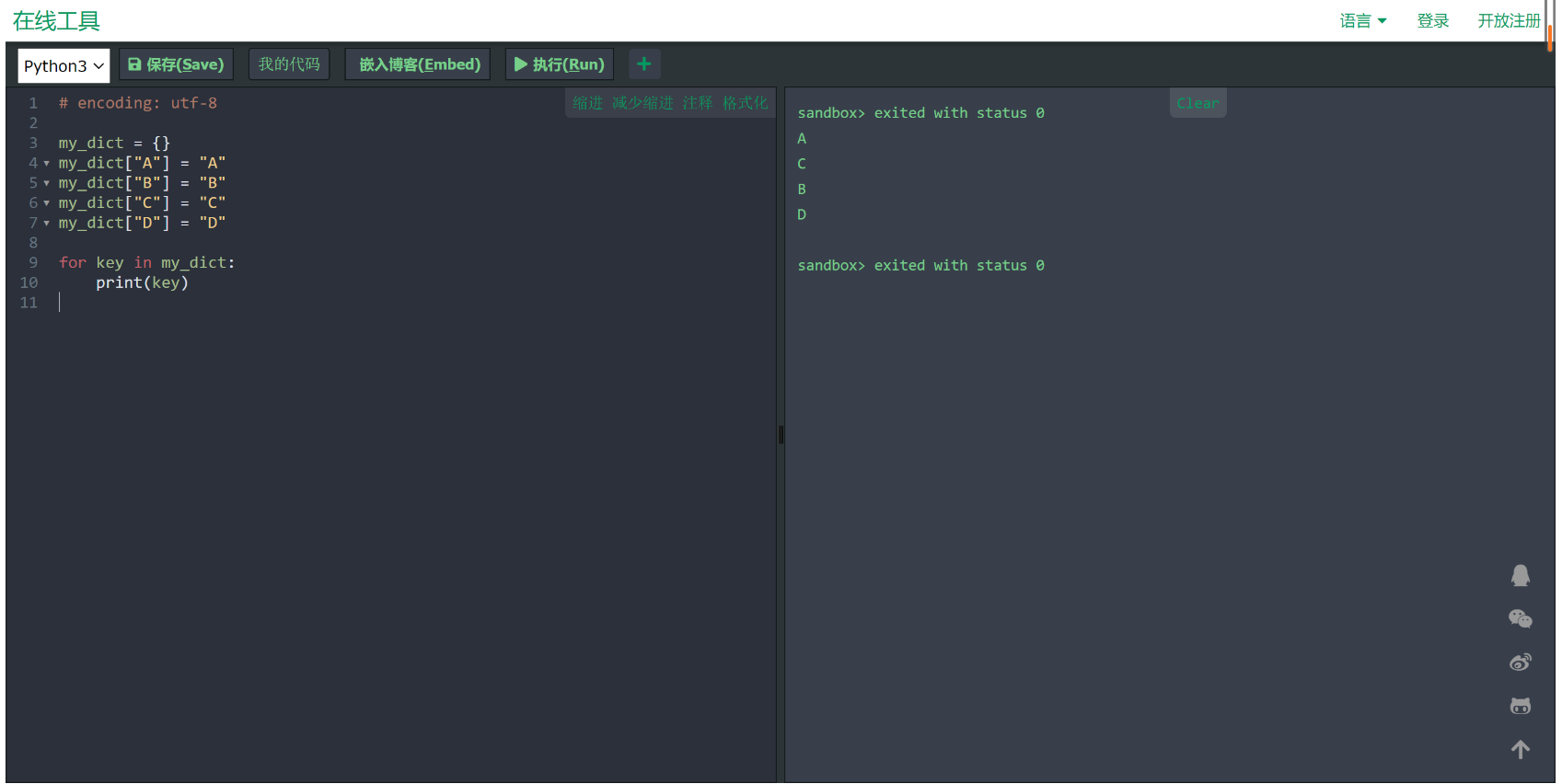
在本地 Python 3.9 版本测试,没有出现乱序的情况
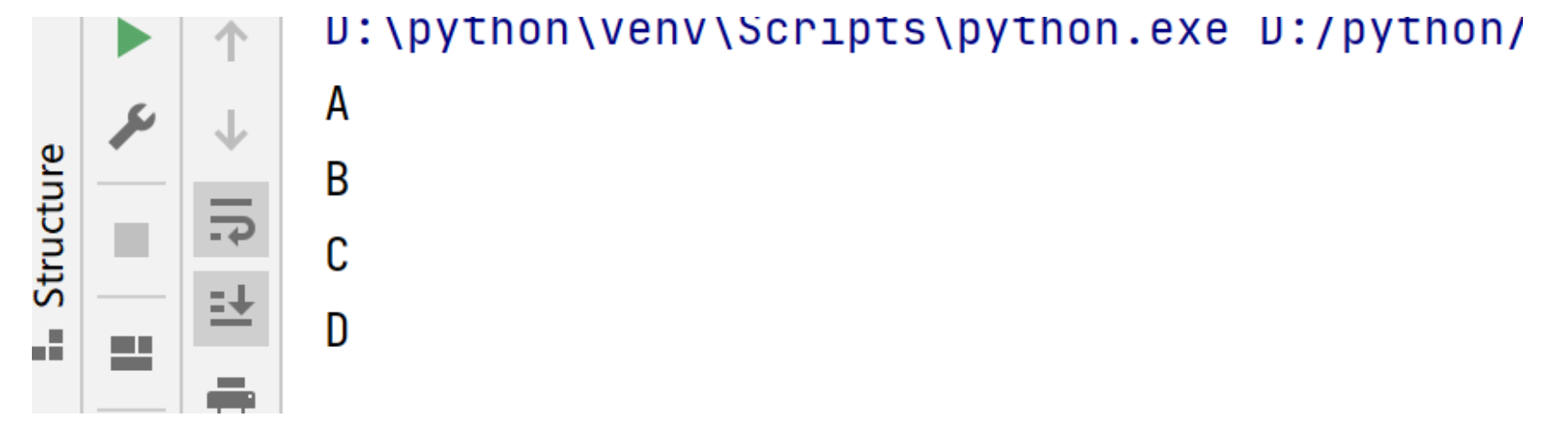
所以再有人问 Python 里面的字典有没有顺序呀,不要直接回答无序了,这玩意现在有顺序。
字典这种键值对结构,相较于列表与元组更加适合添加元素、删除元素、查找元素等操作。
字典的创建不在细说,滚雪球第一遍学习的时候,已经涉及了,需要注意的是索引键的时候,如果键不存在,会出现 KeyError 错误,该错误属于极其常见错误。
♾️ python 代码:my_dict = {}
my_dict["A"] = "A"
my_dict["B"] = "B"
my_dict["C"] = "C"
my_dict["D"] = "D"
print(my_dict["F"])错误提示如下:
♾️ python 代码:Traceback (most recent call last):
File ".\demo.py", line 7, in <module>
print(my_dict["F"])
KeyError: 'F'如果你不希望此异常出现,在索引键的时候使用 get(key,default) 函数即可。
♾️ python 代码:print(my_dict.get("F","None"))再聊集合
集合和字典基本结构相同,最大的区别是集合没有键值对,它是一系列无序且唯一的元素组合。
集合不支持索引操作,也就是说下面的代码肯定是会报错的。
my_set = {"A","B","C"}
print(my_set[0])异常提示为类型错误:TypeError: 'set' object is not subscriptable。
其余重点记忆的就是集合经常用在去重操作上,掌握即可。
字典与集合的排序
基本操作依旧不在过多解释,需要的可以去第一遍滚雪球学习,这里强调一下排序函数,因为涉及了一些扩展知识点,可以先接触一下,后面对于部分内容还会细讲。
学习之前,你要记住,对集合进行 pop 操作,得到的元素是不确定的,因为集合无序,具体你可以测试如下代码:
♾️ pythonpython 代码:my_set = {"A","B","C"}
print(my_set.pop())如果希望对字典排序,按照咱们已知的技术,可以这样进行。
直接使用 sorted 函数即可对字典排序,排序的时候,还可以指定按照键或者值进行排序,例如按照字典值升序排序。
my_dict = {}
my_dict["A"] = "4"
my_dict["B"] = "3"
my_dict["C"] = "2"
my_dict["D"] = "1"
sorted_dict = sorted(my_dict.items(),key=lambda x:x[1])
print(sorted_dict)输出结果如下,得到的结果是按照字典的值进行排序的,这里需要注意的是 lambda 匿名函数在后续的课程将逐步展开
[('D', '1'), ('C', '2'), ('B', '3'), ('A', '4')]集合排序无特别说明,直接使用 sorted 函数即可。
字典与集合的效率问题
字典与集合的效率问题,主要对比的对象是列表,假设现在有一堆学号和体重的数据,咱们需要判断出不同体重数的学生人数。
需求描述如下:
有 4 个学生,按照学号排序形成的元组为 (1,90),(2,90),(3,60),(4,100),最终的结果输出 3(存在三个不同的体重)
按照需求编写代码如下:
列表写法
def find_unique_weight(students):
# 声明一个统计列表
unique_list = []
# 循环所有学生数据
for id, weight in students:
# 如果体重没有在统计列表中
if weight not in unique_list:
# 新增体重数据
unique_list.append(weight)
# 计算列表长度
ret = len(unique_list)
return ret
students = [
(1, 90),
(2, 90),
(3, 60),
(4, 100)
]
print(find_unique_weight(students))
接下来上述代码修改为集合写法
♾️ python 代码:def find_unique_weight(students):
声明一个统计集合
unique_set = set()
# 循环所有学生数据
for id, weight in students:
# 集合会自动过滤重复数据
unique_set.add(weight)
# 计算集合长度
ret = len(unique_set)
return ret代码写完之后,并未发现有太大的差异,但是如果把数据扩大到更大的两集,例如上万数据。
以下代码时间计算函数应用的是 time.perf_counter() 该函数第一次调用时,从计算机系统里随机选一个时间点 A,计算其距离当前时间点 B1 有多少秒。当第二次调用该函数时,默认从第一次调用的时间点 A 算起,距离当前时间点 B2 有多少秒。两个函数取差,即实现从时间点 B1 到 B2 的计时功能,首先结合列表计算的函数,运行下述代码
import time
id = [x for x in range(1, 10000)]
# 体重数据为了计算,也只能从 1 到 10000 了
weight = [x for x in range(1, 10000)]
students = list(zip(id, weight))
start_time = time.perf_counter()
# 调用列表计算函数
find_unique_weight(students)
end_time = time.perf_counter()
print("运算时间为:{}".format(end_time - start_time))运行时间为 1.7326523,每台电脑运行速度不一致,具体看差异。
修改上述代码运行到集合编写的函数上,最终得到的结果为 0.0030606,可以看到在 10000 条数据的量级下就已经产生了如此大的差异,如果数量级在进行上升,差异会再次加大,所以你了解到该用什么内容了吗?
列表和元组
列表与元组那些事儿
列表和元组为何要总放在一起
列表和元组在基础篇已经好好的研究了基础用法,你应该保留一个基本印象就是列表和元组,就是一个可以放置任意数据类型的有序集合,或者当成一个容器也可以。
它们两个最直接的区别就是,列表长度大小不固定,可变,元组长度大小固定,不可变。
在很多地方,会把这种区别叫做动态与静态。
这里最常见的一个错误就是给元组赋值或者修改值了,错误提示如下,出现了要知道原因是啥?
♾️ python 代码:TypeError: 'tuple' object does not support item assignment如何去给元组增加数据呢,我想你应该也比较清楚了,就是新创建一个元组,把新的数据和旧的数据一拼接,搞定。
♾️ python 代码:my_old_tuple = (1, 2, "a", "b")
my_new_tuple = ("c", "d")
my_tuple = my_old_tuple+my_new_tuple
print(my_tuple)对于基础部分,还有要注意的就是,元组如果只有一个元素,一定要这么写 (1,) ,逗号不要遗漏,遗漏了括号里面是啥数据类型,最后得到的就是那个数据类型的数据了。
列表和元组的切片
列表和元组都是有序的,有序就能切片,而切片记住是顾头不顾尾的操作,例如下述代码。
my_tuple = my_old_tuple+my_new_tuple
print(my_tuple[1:3])在刚学习切片的时候,一个比较常见的错误如下,该错误产生的原因是,[] 中括号里面的 : 写成其他符号了。
♾️ python 代码:TypeError: tuple indices must be integers or slices, not tuple负数索引与二者相互转换
列表与切片二者都支持负数索引取值,但是需要知道负数索引是从 -1 开始的,为啥?自己琢磨。
小声嘀咕:还不是因为 0 只有一个
二者也可以互相转换,转换应用的是内置的函数 list 和 tuple,顺着函数学习下去,列表与元组都有一些可以应用的内置函数,这部分在滚雪球第一遍学习的时候,咱已经都搞定了,很简单的知识点。
列表与元组的存储方式
运行下述代码查看运行结果,列表与元组元素数目保持一致。
my_list = ["a", "b", "c"]
print(my_list.__sizeof__())
my_tuple = ("a", "b", "c")
print(my_tuple.__sizeof__())
输出的结果存在差异,相同元素数据的列表与元组,系统给列表分配的空间要大一些
♾️ python 代码:64
48第一个知识点是 __sizeof__(): 表示的打印系统分配空间的大小。
接下来我们对其进行一下基本的测试,从列表检测系统分配是如何进行空间分配的。
♾️ python 代码:my_list = []
print("初始化大小",my_list.__sizeof__())
my_list.append("a")
print("追加1个元素之后的大小",my_list.__sizeof__())
my_list.append("b")
print("追加2个元素之后的大小",my_list.__sizeof__())
my_list.append("c")
print("追加3个元素之后的大小",my_list.__sizeof__())
my_list.append("d")
print("追加4个元素之后的大小",my_list.__sizeof__())
my_list.append("e")
print("追加5个元素之后的大小",my_list.__sizeof__())运行结果为:
♾️ python 代码:初始化大小 40
追加1个元素之后的大小 72
追加2个元素之后的大小 72
追加3个元素之后的大小 72
追加4个元素之后的大小 72
追加5个元素之后的大小 104增加一个元素之后,大小变成了 72,然后连续增加 4 个元素,系统分配的大小都没有变化地 5 个元素,又增加了 32 字节空间,这样已经可以得到结论了:
列表会一次性的增加 4 个元素的空间,当空间使用完毕之后,才会继续增加。
上述代码的原理:
列表从本质上看,是一个动态的数组,列表中并不是存储的真实数据,而是每个元素在内存中的地址(引用),因为列表存储是元素的引用这个特性,所以引用占用的内存空间是相同的,也就是 8 个字节,并且这样可以存储不同类型的数据。
在 64 位的操作系统中,地址占用 8 个字节,如果你的电脑是 32 位,那地址占用的是 4 个字节,注意下即可。
列表和元组的应用场景
简单来说,元组用在固定元素内容的数据上,列表用在可变的数据上,在希望记忆的简单一些,可以直接记成如果只需要 2、3 个元素,就使用 tuple,元素在多就使用 namedtuple,它是一个函数。
使用 namedtuple 需要先进行导入。
from collections import namedtuple
help(namedtuple)函数原型如下:
♾️ python 代码:namedtuple(typename, field_names, *, rename=False, defaults=None, module=None)
# Returns a new subclass of tuple with named fields.先写一段测试代码:
♾️ python 代码:from collections import namedtuple
Point = namedtuple('Point', ['x', 'y'])
p = Point(10, 20)
print(p.x)
print(p.y)前面两个参数需要简单学习一下。
typename:字符串类型的参数,这个参数理解起来比较绕,贴一下官方的解释,namedtuple() 会根据这个 typename, 创建一个子类类名返回出去,例如上文的测试代码中的 Point,创建好的类名称就是 Point ,第二个参数就是以后的类属性了。field_names:用于为创建的元组的每个元素命名,可以传入列表或者元组,例如 ['a', 'b'] 、(a,b),也可以传入'a b' 或 'a,b' 这种被逗号或空格分割的单字符串。
上文中如果你希望看到类被构建的过程,可以增加参数 verbose,但是这个参数在官网也有相关的说明,有的版本是不支持的,在 Python 3.7 之后就没有该属性了。
Changed in version 3.6: The verbose and rename parameters became keyword-only arguments.
Changed in version 3.6: Added the module parameter.
Changed in version 3.7: Removed the verbose parameter and the _source attribute.
Changed in version 3.7: Added the defaults parameter and the _field_defaults attribute.初始化空列表是使用 list() 还是使用 []
该内容可以使用下述代码进行一下效率的测试。
♾️ python 代码:import timeit
a = timeit.timeit('a=list()', number=10000000 )
b = timeit.timeit('a=[]', number=10000000 )
print(a)
print(b)运行结果:
♾️ python 代码:1.6634819
0.5888171999999998结论是 [] 速度更快,因为 list() 是函数调用,效率肯定要低一些。
有了上述函数,你也可以测试一下相同的元素在列表与元组初始化的时候,哪个效率更好。
♾️ python 代码:import timeit
a = timeit.timeit('a=("a","b","c")', number=10000)
b = timeit.timeit('b=["a","b","c"]', number=10000)
print(a)
print(b)运行结果如下:
♾️ python 代码:# 初始化元组
0.0005571000000000048
# 初始化列表
0.002022099999999999类函数、成员函数、静态函数、抽象函数、方法伪装属性
类函数 @classmethod
先直接看代码,再对代码内容进行分析与学习。
♾️ python 代码:class My_Class(object):
# 在类定义中定义变量
cls_var = "类变量"
def __init__(self):
print("构造函数")
self.x = "构造函数中的属于实例变量"
# 类方法,第一个参数必须默认传类,一般习惯用 cls。
@classmethod
def class_method(cls):
print("class_method 是类方法,类名直接调用")
# 类方法不可以调用类内部的对象变量(实例变量)
# print(cls.x)
# 类方法可以通过类名直接调用,也可以通过对象来调用
# 即使通过实例调用类方法,Python 自动传递的也是类,而不是实例
My_Class.class_method()
my_class_dom = My_Class()
# 通过类的对象调用
my_class_dom.class_method()
首先要掌握的是类函数的定义格式,在普通函数的前面添加装饰器 @classmethod,该函数就会转换为类函数,同时函数的第一个参数默认是 cls,该变量名可以任意,建议使用成 cls,这个是程序员之间的约定。
@classmethod
def class_method(cls):同时类函数在调用的时候,可以通过 类名. 的形式进行调用,也可以通过 对象. 的形式调用,不过这两种调用都只是将类传递到了函数内部,不存在差异。
类函数不能调用实例变量,只能调用类变量,所谓类变量就是在类中独立声明,不在任何函数中出现的变量。在上述代码中,类变量声明部分代码如下:
class My_Class(object):
在类定义中定义变量
cls_var = "类变量"
在 Python 中,大部分 @classmethod 装饰的函数末尾都是 return cls(XXX), return XXX.__new__ () 也就是 @classmethod 的一个主要用途是作为构造函数。
静态函数 @staticmethod
先掌握一个概念,静态函数不属于它所在的那个类,它是独立于类的一个单独函数,只是寄存在一个类名下,先建立这个基本概念,后面学起来就简单很多了。
class My_Class(object):
# 类变量
cls_var = "类变量"
def __init__(self):
# 在构造函数中创建变量
self.var = "实例变量"
# 普通的对象实例函数
def instance_method(self):
# 可以访问类变量
print(self.cls_var)
# 可以访问实例变量
print(self.var)
print("实例化方法")
@staticmethod
def static_method():
print(My_Class.cls_var)
# 无法访问到实例变量
# print(My_Class.var)
# print(self.var)
print("静态方法")
my_class = My_Class()
my_class.instance_method()
# 通过对象访问
my_class.static_method()
# 类名直接访问
My_Class.static_method()
即使修改成下述代码,也是错误的,静态函数的第一个参数不是实例对象 self,或者可以理解为静态函数没有隐形参数,如需要传递参数,在参数列表中声明即可。
@staticmethod
def static_method(self):
print(My_Class.cls_var)
# 无法访问到实例变量
# print(My_Class.var)
print(self.var)
print("静态方法")在同一个类中,调用静态方法,使用 类名.函数名() 的格式。
类函数与静态函数在继承类中的表现
先创建一个父类,其中包含两个静态函数与一个类函数。
♾️ python 代码:class F(object):
@staticmethod
def f_static(x):
print("静态方法,有 1 个参数")
print(f"f_static:✅")
@staticmethod
def f_static_1():
print("静态方法,无参数")
return F.f_static(10)
@classmethod
def class_method(cls):
print("父类中的类方法")
return F.f_static(12)
f = F()
f.f_static(11)
f.f_static_1()
f.class_method()
再编写一个 S 类继承自 F 类:
♾️ python 代码:class S(F):
@staticmethod
def f_static(y):
print("子类中重载了父类的静态方法")
print(f"子类中的参数{y}")
@classmethod
def class_method(cls):
print("子类中的类方法")
s = S()
s.f_static(110)
s.class_method()
S.class_method()测试之后,基本结论如下:
如果在子类中覆盖了父类的静态函数,那调用时使用的是子类自己的静态函数,
如果在子类中没有覆盖父类的静态函数,那调用时使用的是父类的静态函数,
类函数同样遵循该规则
如果希望在子类中调用父类的属性或者函数,请使用 父类名. 的形式实现。
抽象函数 @abstractmethod
被 @abstractmethod 装饰的函数为抽象函数,含抽象函数的类不能实例化,继承了含抽象函数的子类必须覆盖所有抽象函数装饰的方法,未被装饰的可以不重写。
抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化,实现代码如下:
♾️ python 代码:import abc
class My_Class(abc.ABC):
@abc.abstractmethod
def abs_method(self):
pass
def show(self):
print("普通")
class M(My_Class):
def abs_method(self):
print('xxx')
mm = M()
mm.abs_method()抽象基类中学习还需要了解元类相关知识,在第三轮滚雪球学 Python 中将为你展开这部分内容。
方法伪装属性
在 Python 面向对象的编码过程中,对象.属性 来获取属性的值,使用 对象.方法() 来调用方法,通过装饰器 @property 可以将一个方法伪装成属性,从而使用 对象.方法 没有括号的形式调用。代码非常简单:
class My_Class(object):
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
m = My_Class("酒笙")
print(m.name)
这种写法最直接的应用,就是将部分属性变成只读属性,例如,上述代码,你无法通过下述代码对 name 进行修改。
class My_Class(object):
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
m = My_Class("酒笙")
m.name = "土豆白菜"
print(m.name)如果希望方法伪装的属性具备修改和删除功能,需要参考下述代码:
♾️ python 代码:class My_Class(object):
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
@name.setter
def name(self, name):
self.__name = name
@name.deleter
def name(self):
del self.__name
m = My_Class("酒笙")
m.name = "土豆白菜"
print(m.name)
上述代码在将 name 方法伪装成属性之后,可以通过 @name.setter 和 @name.deleter 对同名的 name 方法进行装饰,从而实现了修改与删除功能。
所以一般使用方法伪装属性的步骤是:
@property装饰器,可以用来将类中的方法伪装成属性;@方法名.setter装饰器,在修改伪装成属性的方法值时会调用它;@方法名.deleter装饰器,在删除伪装成属性的方法值时会调用它。
如果你觉得这个比较麻烦,还存在一种方法伪装属性的方式。使用 property 函数,原型如下
# 最后一个参数是字符串,调用 实例.属性.__doc__ 时的描述信息
property(fget=None, fset=None, fdel=None, doc=None)通过上述函数将方法伪装成属性的代码为:
♾️ python 代码:class My_Class(object):
def __init__(self, name):
self.__name = name
def del_name(self):
del self.__name
def set_name(self, name):
self.__name = name
def get_name(self):
return self.__name
# 将方法伪装成属性
name = property(get_name, set_name, del_name)
m = My_Class("酒笙")
print(m.name)
m.name = "土豆白菜"
print(m.name)
del m.namesys 库、os 库、 getopt 库 与 filecmp 库
os库
在 Python 中 os 库提供了基本的操作系统交互功能,该库下包含大量与文件系统、操作系统相关的函数,通过 dir 函数可以查看。
import os
print(dir(os))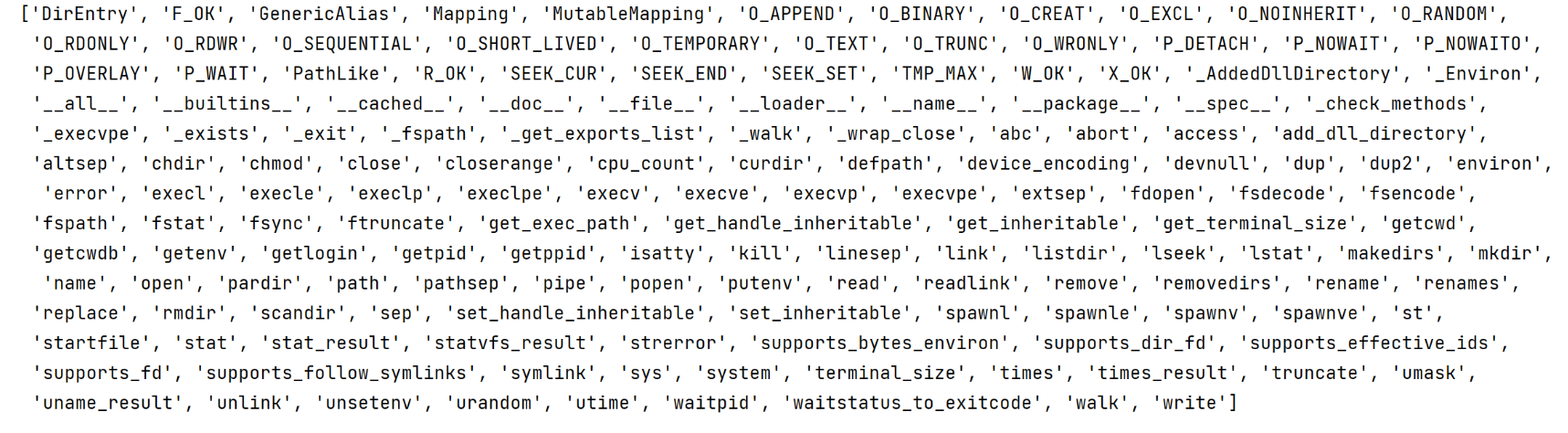
这些函数主要分为几类。
- 路径操作:
os.path子库,处理文件路径及信息; - 进程管理:启动系统中其它程序;
- 环境参数:获得系统软硬件信息等环境参数。
os 库路径操作
os.path 在 os 库中用于提供操作和处理文件路径相关函数,常见的函数清单如下:
| 函数名 | 简介 |
|---|---|
| os.path.abspath(path) | 返回绝对路径 |
| os.path.normpath(path) | 规范 path 字符串形式 |
| os.path.realpath(path) | 返回 path 的真实路径 |
| os.path.dirname(path) | 返回文件路径 |
| os.path.basename(path) | 返回文件名 |
| os.path.join(path1[, path2[, …]]) | 把目录和文件名合成一个路径 |
| os.path.exists(path) | 如果路径 path 存在,返回 True;如果路径 path 不存在,返回 False。 |
| os.path.isfile(path) | 判断路径是否为文件 |
| os.path.isdir(path) | 判断路径是否为目录 |
| os.path.getatime(path) | 返回最近访问时间(浮点型秒数) |
| os.path.getmtime(path) | 返回最近文件修改时间 |
| os.path.getsize(path) | 返回文件大小,如果文件不存在就返回错误 |
模块导入使用下述方式:
♾️ pythpn 代码:import os.path
# import os.path as op
variate = os.path.abspath(__file__)
print(variate)函数的参数都是 path,在传入的时候,特备要注意原生字符串的应用,还有要区分绝对路径和相对路径的问题。
由于 path 相关的库比较简单,每个内容都尝试一遍即可掌握,其它内容可以在 手册 进行学习。
os 库进程管理
该内容主要用于在 Python 中执行程序或命令 Command,函数原型为:
♾️ python 代码:os.system(command)例如,在 Python 中唤醒画板程序。
♾️ python 代码:os.system("c:\windows/system32/mspaint.exe")除了 system 函数以外,还有一个 os.exec 函数族相关知识。具体可以查看下述函数的用法:
os.execl(path, arg0, arg1, …)
os.execle(path, arg0, arg1, …, env)
os.execlp(file, arg0, arg1, …)
os.execlpe(file, arg0, arg1, …, env)
os.execv(path, args)
os.execve(path, args, env)
os.execvp(file, args)
os.execvpe(file, args, env)
这些函数都将执行一个新程序,以替换当前进程
os 库运行环境相关参数
环境参数顾名思义就是改变系统环境信息,或者理解为 Python 运行环境相关信息。
通过下述属性,可以获取环境变量:
♾️ python 代码:os.environ如果希望获取操作系统类型,使用 os.name,目前只有 3 个值:分别是 posix , nt , java
函数部分,主要掌握的函数有:
- os.chdir(path):修改当前程序操作的路径;
- os.getcwd():返回程序运行的路径;
- os.getlogin():获取当前登录用户名称;
- os.cpu_count():获得当前系统的 CPU 数量;
- os.urandom(n):返回一个有 n 个 byte 长的一个随机字符串,用于加密运算。
sys 库
该库主要维护一些与 Python 解释器相关的参数变量和方法。
常见属性如下sys.argv
获取命令行参数列表,第一个元素是程序本身。
使用方式如下:
♾️ python 代码:import sys
print(sys.argv)接下来通过控制台运行 python 程序时,需要携带参数,下述代码 312.py 是 python 文件名,1、2、3 是后缀的参数。
python 312.py 1 2 3执行程序之后,得到的结果为:
♾️ python 代码:['312.py', '1', '2', '3']第一个是文件名,后面依次是传递进来的参数。
sys.platform
获取 Python 运行平台的信息,结果比 os.name 要准确。
sys.path获取 PYTHONPATH 环境变量的值,一般用作模块搜索路径。
import sys
print(sys.path)sys.modules
以字典的形式获取所有当前 Python 环境中已经导入的模块。
sys.stdin,sys.stdout,sys.stderrsys.stdin , sys.stdout ,sys.stderr 变量包含与标准 I/O 流对应的流对象。
import sys
# 标准输出, sys.stdout.write() 的形式就是 print() 不加'\n' 的形式。
sys.stdout.write("hello")
sys.stdout.write("world")sys.stdin 标准输入,等价于 input。
sys.ps1 和 sys.ps2
指定解释器的首要和次要提示符。仅当解释器处于交互模式时,它们才有定义。具体测试如下:
PS > python
Python 3.7.3 (v3.7.3:xxxxxx, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
import sys
sys.ps1
'>>> '
sys.ps1 = "***"
***print("hello")
hello常见方法如下
sys.exit(n)
退出 Python 程序,exit(0)表示正常退出。
当参数非 0 时,会引发一个 SystemExit 异常,可以在程序中捕获该异常。参数也可以称为状态码。
常见方法如下
sys.exit(n)
退出 Python 程序,exit(0)表示正常退出。
当参数非 0 时,会引发一个 SystemExit 异常,可以在程序中捕获该异常。参数也可以称为状态码。
sys.getdefaultencoding()、sys.setdefaultencoding() 、sys.getfilesystemencoding()
sys.getdefaultencoding():获取系统当前编码,有的博客中写默认为ascii,但是我本地默认为utf-8;sys.setdefaultencoding():设置系统的默认编码;sys.getfilesystemencoding():获取文件系统使用编码方式,默认 utf-8。
sys.getrecursionlimit() 、 sys.setrecursionlimit()
获取 Python 的最大递归数目和设置最大递归数目
sys.getswitchinterval()、sys.setswitchinterval(interval)
获取和设置解释器的线程切换间隔时间(单位为秒)
还有很多方法,也是记忆层面的知识,备注下备注下 官方手册 地址。
getopt 库
在控制台运行命令的时候,存在一种需求是传递参数,例如安装第三方模块,使用的命令是:
pip install xxxx -i http://xxxxxx在 Python中也可以实现类似的效果,getopt 库提供了解析命令行参数 sys.argv 的功能。
通过 dir 查看该库中提供的方法不多,具体如下:
♾️ python 代码:'do_longs', 'do_shorts', 'error', 'getopt', 'gnu_getopt', 'long_has_args', 'os', 'short_has_arg'重点函数是 getopt.getopt() 该函数原型如下:
getopt(args, shortopts, longopts=[])- args:程序的命令行参数,不包括程序文件名称,一般传递 sys.argv[1:];
- shortopts:定义 -x 或者 -x <值> 形式的短参数,带值的增加 :,例如 xyz:m:,表示可解析 -x -y -z <值> -d <值> 的参数;
- longopts:定义 --name,--name <值> 形式的长参数,带值的增加 =。
下面通过一个列表直接模拟 sys.argv 接收到的参数。
♾️ python 代码:import getopt
import sys
sys.argv = ["demo.py", "-i", "-d", "baidu.com", "arg1"]
opts, args = getopt.getopt(sys.argv[1:], "id:")
print(opts)
print(args)
返回值由两个元素组成:第一个是 (option, value)对的列表;
第二个是在去除该选项列表后余下的程序参数列表(这也就是 args 的尾部切片)。
除了短参数以外,还有长参数,测试代码如下:
♾️ python 代码:my_str = "demo.py -i -d baidu.com --name bai arg1"
sys.argv = my_str.split()
print(sys.argv)
opts, args = getopt.getopt(sys.argv[1:], "id:",["name="])
print(opts)
print(args)运行代码之后,参数也成功的被解析了出来。
♾️ python 代码:['demo.py', '-i', '-d', 'baidu.com', '--name', 'bai', 'arg1']
[('-i', ''), ('-d', 'baidu.com'), ('--name', 'bai')]
['arg1']如果程序异常,会出现参数解析错误,异常类为 getopt.GetoptError。
my_str = "demo.py -i -d baidu.com --name bai arg1"
sys.argv = my_str.split()
print(sys.argv)
opts, args = getopt.getopt(sys.argv[1:], "id:")
print(opts)
print(args)该代码由于没有匹配长参数,出现错误为:
getopt.GetoptError: option --name not recognized
filecmp 库
该库用来提供比较目录和文件的功能。
文件比较函数有 cmp()、cmpfiles(),
目录比较使用 filecmp 库中的 dircmp 类。
filecmp.cmp()、filecmp.cmpfiles()
filecmp.cmp() 用于比较两个文件内容是否一致,如果文件内容匹配,函数返回 True,否则返回 False。
import filecmp
x = filecmp.cmp("312.py","312.py")
print(x)filecmp.cmpfiles() 函数用于比较两个文件夹内指定文件是否相等。
函数原型如下:
filecmp.cmpfiles(dir1, dir2, common[, shallow])
#参数 dir1, dir2 指定要比较的文件夹,参数 common 指定要比较的文件名列表。
#函数返回包含 3 个 list 元素的元组,分别表示匹配、不匹配以及错误的文件列表。
#错误的文件指的是不存在的文件,或文件被琐定不可读,或没权限读文件,或者由于其他原因访问不了该文件。测试代码如下:
♾️ python 代码:import filecmp
x = filecmp.cmpfiles("../53","../54",["demo.py","demo1.py"])
print(x)目录比较
主要看类的构造函数就可以了。
class filecmp.dircmp(a, b, ignore=None, hide=None)
参数说明如下:- a, b:目录;
- ignore:关键字参数,需要忽略的文件名列表, 默认为 filecmp.DEFAULT_IGNORES;
- hide:关键字参数,需要隐藏的文件名列表, 默认为 [os.curdir, os.pardir]。
使用 dircmp 生成一个比较对象之后,就可以获取各个属性值了。具体可以直接在这个网页进行查询。
Python 内置模块之 re 库
re 库的应用
re 库是 Python 中处理正则表达式的标准库,本篇博客介绍 re 库的同时,会简单介绍一下正则表达式语法,如果想深入学习正则表达式,还需要好好下一番功夫。
正则表达式语法
正则表达式语法由字符和操作符构成,初期阶段掌握下述这些内容即可。
| 操作符 | 说明 | 例子 |
|---|---|---|
| . | 任何单个字符,极少不能匹配 | |
| [] | 字符集,对单个字符给出取值范围 | [abc] 表示匹配 a、b、c,[a-z] 表示 a 到 z 单个字符 |
| [^] | 非字符集,对单个字符给出排除范围 | [^abc] 表示匹配 非 a、非 b、非 c 的单个字符 |
| * | 前一个字符 0 次或无限次扩展 | abc* 表示 ab、abc、abcc、abccc 等 |
| + | 前一个字符 1 次或无限次扩展 | abc+ 表示 abc、abcc、abccc 等 |
| ? | 前一个字符 0 次或 1 次 | abc? 表示 ab、abc |
| / | 左右表达式任意一个 | abc/def 表示 abc 或者 def |
| {m} | 扩展前 1 个字符 m 次 | ab{2}c,表示 abbc |
| {m,n} | 扩展前 1 个字符 m 到 n 次 | ab{1,2}c,表示 abc、abbc |
以上表示仅仅为正则表达最基础部分内容,如果希望深入研究正则表达式,建议寻找更加全面的资料进行学习,本文只做药引。
re 库基本用法
re 库主要函数如下:
- 基础函数:
compile; - 功能函数:
search、match、findall、split、finditer、sub。
在正式学习之前,先了解一下原生字符串。
在 Python 中,表示原生字符串,需要在字符串前面加上 r。
例如 my_str = 'i'am xiangpica' 在程序中会直接报错,如果希望字符串中 ' 可以正常运行,需要加上转移字符 \,修改为 my_str = 'i\'am xiangpica'。
但这样结合上文正则表达式中的操作符,就会出现问题,因为 \ 在正则表达式中是有真实含义的,如果你使用 re 库去匹配字符串中的 \,那需要使用 4 个反斜杠,为了避免这种情况出现,引入了原生字符串概念。
# 不使用原生字符串的正则表达式 "\\\\"
# 使用原生字符串的正则表达式 r"\\"在后文会有实际的应用。
接下来在学习一个案例,例如下述代码:
♾️ python 代码:my_str='C:\number'
print(my_str)C:
umber本段代码的输出效果如下,\n 被解析成了换行,如果想要屏蔽这种现象,使用 r 即可:
my_str=r'C:\number'
print(my_str)输出 C:\number。
re 库相关函数说明
re.search 函数
该函数用于,在字符串中搜索正则表达式匹配到的第一个位置的值,返回 match 对象。
函数原型如下:
re.search(pattern,string,flags=0)需求:在字符串 酒笙 good good 中匹配 酒笙。
import re
my_str='酒笙 good good'
pattern = r'酒笙'
ret = re.search(pattern,my_str)
print(ret)返回结果:<re.Match object; span=(2, 5), match='酒笙'>。
search 函数的第三个参数 flags 表示正则表达式使用时的控制标记。
re.I,re.IGNORECASE:忽略正则表达式的大小写;re.M,re.MULTILINE:正则表达式中的 ^ 操作符能够将给定字符串的每行当做匹配的开始;re.S,re.DOTALL:正则表达式中的.操作符能够匹配所有字符。
最后将匹配到的字符串进行输出,使用下述代码即可实现。
♾️ python 代码:import re
my_str = '酒笙 good good'
pattern = r'酒笙'
ret = re.search(pattern, my_str)
if ret:
print(ret.group(0))re.match 函数
该函数用于在目标字符串开始位置去匹配正则表达式,返回 match 对象,未匹配成功返回 None,函数原型如下:
♾️ python 代码:re.match(pattern,string,flags=0)一定要注意是目标字符串开始位置。
♾️ python 代码:import re
my_str = '酒笙 good good'
pattern = r'梦' # 匹配到数据
pattern = r'good' # 匹配不到数据
ret = re.match(pattern, my_str)
if ret:
print(ret.group(0))re.match 和 re.search 方法都是一次最多返回一个匹配对象,如果希望返回多个值,可以通过在 pattern 里加括号构造匹配组返回多个字符串。
re.findall 函数
该函数用于搜索字符串,以列表格式返回全部匹配到的字符串,函数原型如下:
♾️ python 代码:re.findall(pattern,string,flags=0)测试代码如下:
♾️ python 代码:import re
my_str = '酒笙 good good'
pattern = r'good'
ret = re.findall(pattern, my_str)
print(ret)re.split 函数
该函数将一个字符串按照正则表达式匹配结果进行分割,返回一个列表。
函数原型如下:
re.split(pattern, string, maxsplit=0, flags=0)re.split 函数进行分割的时候,如果正则表达式匹配到的字符恰好在字符串开头或者结尾,返回分割后的字符串列表首尾都多了空格,需要手动去除,例如下述代码:
import re
my_str = '1酒笙1good1good1'
pattern = r'\d'
ret = re.split(pattern, my_str)
print(ret)运行结果:
♾️ bash 代码:['', '酒笙', 'good', 'good', '']切换为中间的内容,则能正确的分割字符串。
♾️ python 代码:import re
my_str = '1酒笙1good1good1'
pattern = r'good'
ret = re.split(pattern, my_str)
print(ret)如果在 pattern 中捕获到括号,那括号中匹配到的结果也会在返回的列表中。
♾️ python 代码:import re
my_str = '1酒笙1good1good1'
pattern = r'(good)'
ret = re.split(pattern, my_str)
print(ret)运行结果,你可以对比带括号和不带括号的区别进行学习:
♾️ bash 代码:['1酒笙1', 'good', '1', 'good', '1']maxsplit 参数表示最多进行分割次数, 剩下的字符全部返回到列表的最后一个元素,例如设置匹配 1 次,得到的结果是 ['1酒笙1', '1good1']。
re.finditer 函数
搜索字符串,并返回一个匹配结果的迭代器,每个迭代元素都是 match 对象。函数原型如下:
♾️ python 代码:re.finditer(pattern,string,flags=0)测试代码如下:
♾️ python 代码:import re
my_str = '1酒笙1good1good1'
pattern = r'good'
# ret = re.split(pattern, my_str,maxsplit=1)
ret =re.finditer(pattern, my_str)
print(ret)re.sub 函数
在一个字符串中替换被正则表达式匹配到的字符串,返回替换后的字符串,函数原型如下:
♾️ python 代码:re.sub(pattern,repl,string,count=0,flags=0)其中 repl 参数是替换匹配字符串的字符串,count 参数是匹配的最大替换次数。
import re
my_str = '1酒笙1good1good1'
pattern = r'good'
ret = re.sub(pattern, "nice", my_str)
print(ret)运行之后,得到替换之后的字符串:
♾️ bash 代码:1酒笙1nice1nice1re 库其它函数
其它比较常见的函数有:re.fullmatch(),re.subn(),re.escape(),更多内容可以查阅 官方文档,获取一手资料。
re 库的面向对象写法
上文都是函数式写法,re 库可以采用面向对象的写法,将正则表达式进行编译之后,多次操作。核心用到的函数是 re.compile。
该函数原型如下:
♾️ pythn 代码:regex = re.compile(pattern,flags=0)其中 pattern 是正则表达式字符串或者原生字符串。
测试代码如下:
♾️ python 代码:import re
my_str = '1酒笙1good1good1'
# 正则对象
regex = re.compile(pattern = r'good')
ret = regex.sub("nice", my_str)
print(ret)上述代码将正则表达式编译为一个正则对象,后面在 regex.sub 函数中就不需要在写正则表达式了,使用时,只需要将编译好的 regex 对象替换所有的 re 对象,再去调用对应的方法。
re 库的 match 对象
使用 re 库匹配字符串之后,会返回 match 对象,该对象具备以下属性和方法。
match 对象的属性
.string:待匹配的文本;.re:匹配时使用的 pattern 对象;.pos:正则表达式搜索文本的开始位置;.endpos:正则表达式搜索文本的结束位置。
测试代码如下:
♾️ python 代码:import re
my_str = '1酒笙1good1good1'
regex = re.compile(pattern = r'g\w+d')
ret = regex.search(my_str)
print(ret)
print(ret.string)
print(ret.re)
print(ret.pos)
print(ret.endpos)结果输出:
♾️ bash 代码:<re.Match object; span=(7, 16), match='good1good'>
1酒笙1good1good1
re.compile('g\\w+d')
0
17match 对象的方法
.group(0):获取匹配后的字符串;.start():匹配字符串在原始字符串的开始位置;.end():匹配字符串在原始字符串的结尾位置;.span():返回(.start(),.end())
因为内容比较简单,具体代码不再展示。
Python 内置模块之 random
random 库是 Python 中生成随机数的标准库,包含的函数清单如下:
- 基本随机函数:
seed、random、getstate、setstate; - 扩展随机函数:
randint、getrandbits、randrange、choice、shuffle、sample; - 分布随机函数:
uniform、triangular、betavariate、expovariate、gammavariate、gauss、lognormvariate、normalvariate、vonmisesvariate、paretovariate、weibullvariate。
发现单词variate出现频率比较高,该但是是变量的意思。
基本随机函数
seed 与 random 函数
seed 函数初始化一个随机种子,默认是当前系统时间。
random 函数 生成一个 [0.0,1.0) 之间的随机小数 。
具体代码如下:
♾️ python 代码:import random
random.seed(10)
x = random.random()
print(x)其中需要说明的是 random.seed 函数, 通过 seed 函数 可以每次生成相同的随机数,例如下述代码:
import random
random.seed(10)
x = random.random()
print(x)
random.seed(10)
y = random.random()
print(y)在不同的代码上获取到的值是不同的,但是 x 与 y 是相同的。
♾️ bash 代码:0.5714025946899135
0.5714025946899135getstate() 和 setstate(state)
getstate 函数用来记录随机数生成器的状态,setstate 函数用来将生成器恢复到上次记录的状态。
# 记录生成器的状态
state_tuple = random.getstate()
for i in range(4):
print(random.random())
print("*"*10)
# 传入参数后恢复之前状态
random.setstate(state_tuple)
for j in range(4):
print(random.random())输出的随机数两次一致。
♾️ bash 代码:0.10043296140791758
0.6183668665504062
0.6964328590693109
0.6702494141830372
**********
0.10043296140791758
0.6183668665504062
0.6964328590693109
0.6702494141830372扩展随机函数
random 扩展随机函数有如下几个:
♾️ python 代码:`randint`、`getrandbits`、`randrange`、`choice`、`shuffle`、`sample`randint 和 randrange
randint 生成一个 [x,y] 区间之内的整数。 randrange 生成一个 [m,n) 区间之内以 k 为步长的随机整数。
测试代码如下:
♾️ python 代码:x = random.randint(1,10)
print(x)
y = random.randrange(1,10,2)
print(y)这两个函数比较简单,randint 函数原型如下:
random.randint(start,stop)参数 start 表示最小值,参数 stop 表示最大值,两头都是闭区间,也就是 start 和 stop 都能被获取到。
randrange 函数原型如下:
random.randrange(start,stop,step)如果函数调用时只有一个参数,默认是从 0 到该参数值,该函数与 randint 区别在于,函数是左闭右开,最后一个参数是步长。
查阅效果,可以复制下述代码运行:
♾️ python 代码:for i in range(3):
print("*"*20)
print(random.randrange(10))
print(random.randrange(5,10))
print(random.randrange(5,100,5))getrandbits(k) 和 choice(seq)
getrandbits 生成一个 k 比特长的随机整数,实际输出的是 k 位二进制数转换成的十进制数。 choice 从序列中随机选择一个元素。
x = random.getrandbits(5)
print(x)
# 生成的长度是 00000-11111getrandbits(k) 函数可以简单描述如下:输出一个 [ 0 , 2 k − 1 ] [0,2^k-1] [0,2k−1] 范围内一个随机整数,k 表示的是 2 进制的位数。
choice 就比较简单了,从列表中返回一个随机元素。
import random
my_list = ["a", "b", "c"]
print(random.choice(my_list))shuffle(seq) 和 sample(pop,k)
shuffle 函数用于将序列中的元素随机排序,并且原序列被修改。 sample 函数用于从序列或者集合中随机选择 k 个选择,原序列不变。
my_list = [1,2,3,4,5,6,7,8,9]
random.shuffle(my_list)
print(my_list)shuffle 函数只能用于可变序列,不可变序列(如元组)会出现错误。
my_list = ["梦想", "酒笙", 1, 2, [3, 4]]
print(my_list)
ls = random.sample(my_list, 4)
print(ls)分布随机函数
该部分涉及的比较多,重点展示重要和常见的一些函数。
uniform(a,b) 、betavariate 和 triangular 函数
uniform 生成一个 [a,b] 之间的随机小数,采用等概率分布。 betavariate 生成一个 [0,1] 之间的随机小数,采用 beta 分布。 triangular 生成一个 [low,high] 之间的随机小数,采用三角分布。
在使用 uniform 时候需要注意,如果 a<b,那么生成一个 b-a 之间的小数。
for i in range(3):
print(random.uniform(4, 1))其它分布随机函数
以下都是生成随机数的方法,只是底层核心算法不同。
expovariate:生成一个(0,∞)之间的随机整数,指数分布;gammavariate:采用 gamma 分布;gauss:采用高斯(正太)分布;lognormvariate:对数正太分布;normalvariate:正太分布;vonmisesvariate:冯米赛斯分布;paretovariate:帕累托分布;weibullvariate:韦伯分布。
Python 哈希表与可哈希对象
哈希表(散列表)
哈希是从 Hash 音译过来的,哈希表(hashtable),也叫做散列表。
哈希表是键值对的无序集合,其每个键都是唯一的,核心算法是通过索引去查找值,Python 中的字典符合哈希表结构,字典中每个键对应一个值,my_dict={"key1":"value1","key2":"value2"}。
哈希是使用算法将任意大小的数据映射到固定长度输出的过程,该输出就是哈希值。
哈希算法可以创建高性能的数据结构,该结构可以快速存储和访问大量数据,哈希值通过哈希函数计算。
哈希函数,本质上是键到值的映射关系;
哈希表本质上就是一个数组,存储的是经过哈希函数运算之后得到的值;
哈希值是唯一标识数据的固定长度的数值。
这些都属于概念层面的知识,初期了解即可,后面随着应用会逐步掌握。
可哈希与不可哈希
这部分在 官方文档 说的比较绕,简单说一下的结论(也是大家共识的),一个对象(Python 中万物皆对象)在生命周期内,保持不变,就是可哈希的(hashable)。
还有一个更简单的证明办法,在 Python 中能插入 set 集合的元素是可哈希的,例如下述代码:
my_set = set()
test = [1, 3.14, 'hello', (2, 3), {'key': 1}, [1, 2], {3,6}]
my_set.add(test[0])
my_set.add(test[1])
my_set.add(test[2])
my_set.add(test[3])
# my_set.add(test[4])
# my_set.add(test[5])
# my_set.add(test[6])测试之后得到的结论是:
- 可以被哈希的数据结构:
int、float、str、tuple; - 不可以被哈希的数据结构:
dict、list、set。
加上之前滚雪球学到的知识,可以了解到,可以被哈希的数据类型都是不可变的,而不可以被哈希的数据类型是可变的,有点绕,稍微停顿一下,多读两遍即可。
可哈希的对象通常用作字典的键和集合的成员,因为这些数据结构在内部使用哈希值。
最终结论: 可哈希 ≈ 不可变。
Python hash() 函数
hash 函数用于获取一个对象的哈希值,语法结果为 hash(object),返回值是对象的哈希值, 哈希值是整数。
使用方式非常简单:
print(hash('test'))
print(hash(1))
# 注意下面使用不可哈希对象会出现错误
# hash([1,2,3])hashlib 模块
hashlib 提供了常见的摘要算法,具体如下:
md5()、sha1()、sha224()、sha256()、sha384()、sha512()、blake2b()、blake2s()、sha3\_224()、sha3\_256()、sha3\_384()、 sha3\_512()、 shake\_128()、shake\_256()
使用 dir(hashlib) 即可获取上述所有可用方法。
MD5 是最常见的摘要算法,生成结果是固定的 16 字节,通常用一个 32 位的 16 进制字符串表示,示例代码如下:
import hashlib
# MD5算法
md5 = hashlib.md5()
data = "hello world"
md5.update(data.encode('utf-8'))
# 计算 hash 值,拿到加密字符串
print(md5.hexdigest())SHA1 算法更安全,它的结果是 20 字节长度,通常用一个 40 位的 16 进制字符串表示。而比 SHA1 更安全的算法是 SHA256 和 SHA512 等,不过越安全的算法越慢,并且摘要长度更长。
Python 之作用域下的 global 和 nonlocal 关键字
global 和 nonlocal 作用域
该部分内容涉及 Python 变量作用域相关知识,变量作用域指的是变量的有效作用范围,直接理解就是 Python 中的变量不是任意位置都可以访问的,有限制条件。
一般情况下变量的作用域变化范围是 块级、函数、类、模块、包等,级别是从小到达。Python 中是没有块级作用域的,所以我们在写代码的时候,下面的代码是正确的。
♾️ python 代码:if True:
x = "hello world"
# 因为没有块级作用域,故 if 代码块中的变量 x 可以被外部访问到
print(x)在 Python 中常见的块级作用域有 if 语句、for 语句、while 语句、with 上下文语句。
Python 中的作用域
上文已经提及了作用域是 Python 程序可以直接访问一个变量的作用范围,Python 的作用域一共有 4 种,分别如下:
- L(Local):最内层,包含局部变量,例如函数(方法)内部;
- E(Enclosing):包含非局部(nonlocal)也非全局(nonglobal)的变量,在嵌套函数中,函数 A 包含函数 B,在 B 中去访问 A 中的变量,作用域就是 nonlocal,直白理解就是闭包函数外的函数中的变量;
- G(Global):代码最外层,全局变量;
- B(Built-in):包含内建变量。
一个比较经典的案例如下:
♾️ python 代码:# 内建作用域 Built-in
x = int(5/2)
# 全局作用域 Global
global_var = 0
def outer():
# 闭包函数外的函数中 Enclosing
out_var = 1
def inner():
# 局部作用域 Local
inner_var = 2在 Python 中变量寻找的顺序是从内到外,先局部,然后外部,在全局,在内建,这种规则叫做 LEGB 规则。
增加以下学习的趣味性,你可以研究下述代码中变量是如何变化的。
♾️ python 代码:len = len([])
def a():
len = 1
def b():
len = 2
print(len)
b()
a()global 关键字
定义在函数内部的变量拥有一个局部作用域,定义在函数外部的变量拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。
♾️ python 代码:# 全局变量
x = 0
def demo():
# 此时的 x 是局部变量
x = 123
print("函数内是局部变量 x = ", x)
demo()
print("函数外是全局变量 x= ", x)输出结果,函数内部是 123,函数外部依旧是 0。
如果希望函数内部(内部作用域)可以修改外部作用域的变量,需要使用 global 关键字。
# 全局变量
x = 0
def demo():
# 此时的 x 是全局变量
global x
x = 123
print("函数内是局部变量 x = ", x)
demo()
print("函数外是全局变量 x= ", x)此时输出的就都是 123 了,还有一点需要注意,在函数内容如果希望修改全局变量的值,global 关键字一定要写在变量操作前。
def demo():
# 此时的 x 是全局变量
x = 123
global x
print("函数内是局部变量 x = ", x)该代码会出现语法错误:
♾️ bash 代码:SyntaxError: name 'x' is assigned to before global declaration除了以上知识外,要记住在函数内部使用一个变量,不修改值的前提下,没有声明,默认获取的是全局变量的值。
♾️ python 代码:x = "全局变量"
def demo():
print(x)
demo()全局变量还存在一个面试真题,经常出现,请问下述代码运行结果。
♾️ python 代码:x = 10
def demo():
x += 1
print(x)
demo()结论是报错,原因就是 demo 函数运行时,会先计算 x+1,对变量进行计算之前需要进行声明与赋值,但是函数内部对 x 没有初始化操作,故报错。
nonlocal 关键字
如果要修改嵌套作用域(Enclosing 作用域)中的变量,需要 nonlocal 关键字,测试代码如下:
def outer():
num = 10
def inner():
# nonlocal 关键字
nonlocal num
num = 100
print(num)
inner()
print(num)
outer()输出结果自行测试,注意 nonlocal 关键字必须是 Python3.X+版本,Python 2.X 版本会出现语法错误:
nonlocal num
^
SyntaxError: invalid syntax`nonlocal 不能代替 global,例如下述代码,注释掉外层函数的变量声明,此时会出现 SyntaxError: no binding for nonlocal 'num' found 错误。
num = 10
def outer():
# 注释掉本行
# num = 10
def inner():
# nonlocal 关键字
nonlocal num
num = 100
print(num)
inner()
print(num)
outer()在多重嵌套中,nonlocal 只会上溯一层,如果上一层没有,则会继续上溯,下述代码你可以分别注释查看结果。
num = 10
def outer():
num = 100
def inner():
num = 1000
def inner1():
nonlocal num
num = 10000
print(num)
inner1()
print(num)
inner()
print(num)
outer()局部变量和全局变量具体有哪些,可以通过 locals() 和 globals() 两个内置函数获取。
x = "全局变量"
def demo():
y = "局部变量"
print(locals())
print(x)
demo()
print(globals())
print(locals())Python 之怎么玩转时间和日期库
Python 日期与时间
在 Python 中是没有原生数据类型支持时间的,日期与时间的操作需要借助三个模块,分别是 time、datetime、calendar。
time 模块可以操作 C 语言库中的时间相关函数,时钟时间与处理器运行时间都可以获取。 datetime 模块提供了日期与时间的高级接口。 calendar 模块为通用日历相关函数,用于创建数周、数月、数年的周期性事件。
在学习之前,还有一些术语要补充一下,这些术语你当成惯例即可。这里在 Python 官方文档中也有相关说明,不过信息比较多,酒笙为你摘录必须知道的一部分。
epoch(纪元) 是时间开始的点,其值取决于平台。
对于 Unix, epoch(纪元) 是 1970年1月1日00:00:00(UTC)。要找出给定平台上的 epoch ,请使用 time.gmtime(0) 进行查看,例如酒笙电脑显示:
time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0)术语 纪元秒数 是指自 epoch (纪元)时间点以来经过的总秒数,通常不包括闰秒。 在所有符合 POSIX 标准的平台上,闰秒都不会记录在总秒数中。
程序员中常把 纪元秒数 称为 时间戳。
time 时间模块
该模块核心为控制时钟时间。
get\_clock\_info 函数
该函数获取时钟的基本信息,得到的值因不同系统存在差异,函数原型比较简单:
♾️ python 代码:time.get_clock_info(name)其中 name 可以取下述值:
monotonic:time.monotonic()perf_counter: time.perf\_counter()process_time: time.process\_time()thread_time: time.thread\_time()time: time.time()
该函数的返回值具有以下属性:
adjustable: 返回 True 或者 False。如果时钟可以自动更改(例如通过 NTP 守护程序)或由系统管理员手动更改,则为 True ,否则为 False ;implementation: 用于获取时钟值的基础 C 函数的名称,就是调用底层 C 的函数;monotonic:如果时钟不能倒退,则为 True ,否则为 False;resolution: 以秒为单位的时钟分辨率( float )。
import time
available_clocks = [
('clock', time.clock),
('monotonic', time.monotonic),
('perf_counter', time.perf_counter),
('process_time', time.process_time),
('time', time.time),
]
for clock_name, func in available_clocks:
print('''
{name}:
adjustable : {info.adjustable}
implementation: {info.implementation}
monotonic : {info.monotonic}
resolution : {info.resolution}
current : {current}
'''.format(
name=clock_name,
info=time.get_clock_info(clock_name),
current=func()))运行结果如下图所示。 
上图显示酒笙的计算机在 clock 与 perf_counter 中,调用底层 C 函数是一致的。
获取时间戳
在 Python 中通过 time.time() 函数获取纪元秒数,它可以把从 epoch 开始之后的秒数以浮点数格式返回。
import time
print(time.time())
# 输出结果 1615257195.558105时间戳大量用于计算时间相关程序,属于必须掌握内容。
获取可读时间
时间戳主要用于时间上的方便计算,对于人们阅读是比较难理解的,如果希望获取可读时间,使用 ctime() 函数获取。
import time
print(time.ctime())
# 输出内容:Tue Mar 9 10:35:51 2021如何将时间戳转换为可读时间,使用 localtime 函数即可。
localtime = time.localtime(time.time())
print("本地时间为 :", localtime)输出结果为 <class 'time.struct_time'> 类型数据,后文将对其进行格式化操作:
本地时间为 : time.struct_time(tm_year=2021, tm_mon=3, tm_mday=9, tm_hour=10, tm_min=37, tm_sec=27, tm_wday=1, tm_yday=68, tm_isdst=0)上述代码中的时间戳最小值是 0,最大值由于 Python 环境和操作系统决定,我本地 64 位操作系统进行测试的时候,得到的数据如下:
♾️ python 代码:import time
localtime = time.localtime(0)
print("时间为 :", localtime)
# 时间为 : time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=8, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0)
localtime = time.localtime(32536799999)
print("时间为 :", localtime)
# 时间为 : time.struct_time(tm_year=3001, tm_mon=1, tm_mday=19, tm_hour=15, tm_min=59, tm_sec=59, tm_wday=0, tm_yday=19, tm_isdst=0)
localtime = time.localtime(99999999999)
print("时间为 :", localtime)
# OSError: [Errno 22] Invalid argument
print(type(localtime))单调时间 monotonic time
monotonic time 从系统启动开始计时,从 0 开始单调递增。
操作系统的时间可能不是从 0 开始,而且会因为时间出错而回调。
该函数原型如下,不需要任何参数,返回一个浮点数,表示小数秒内的单调时钟的值:
♾️ python 代码:time.monotonic()测试代码如下:
♾️ python 代码:print("单调时间",time.monotonic())
# 输出:单调时间 12279.244处理器时钟时间
time() 函数返回的是纪元秒数(时间戳), clock() 函数返回的是处理器时钟时间。
该函数函数的返回值:
- 在第一次调用的时候,返回的是程序运行的实际时间;
- 在第二次之后的调用,返回的是自第一次调用后到这次调用的时间间隔。
需要注意的是 Python 3.8 已移除 clock() 函数,用 time.perf_counter() 或 time.process_time() 方法替代。
t0 = time.clock()
# 运行一段代码
print(time.clock() - t0, "程序运行时间")我使用的 Python 版本较高,提示异常如下:
♾️ bash 代码:time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead t0 = time.clock()性能计数器 time.perf\_counter
perf_counter() 函数的 epoch (纪元)是未定义的。一般使用该函数都是为了比较和计算,不是为了用作绝对时间,该点需要注意下。
该函数用于测量较短持续时间的具有最高有效精度的时钟,包括睡眠状态消耗的时间,使用两次调用才会有效。
测试代码如下:
♾️ python 代码:t0 = time.perf_counter()
# 运行一段代码
for i in range(100000):
pass
print("程序运行时间", time.perf_counter() - t0)与其类似的函数有 perf_counter_ns()、process_time()、process_time_ns(),具体可以查询手册进行学习,先掌握 perf_counter() 函数即可。
时间组件
上文已经涉及了时间组件相关的知识,通过 localtime 得到的 struct_time 类型的数据。
这里涉及到的函数有 gmtime() 返回 UTC 中的当前时间,localtime() 返回当前时区对应的时间,mktime() 接收 struce_time 类型数据并将其转换成浮点型数值,即时间戳。
print("*"*10)
print(time.gmtime())
print("*"*10)
print(time.localtime())
print("*"*10)
print(time.mktime(time.localtime()))struct\_time 类型包含的内容
上述代码返回的数据格式为:
♾️ bash 代码:time.struct_time(tm_year=2021, tm_mon=3, tm_mday=9, tm_hour=12, tm_min=50, tm_sec=35, tm_wday=1, tm_yday=68, tm_isdst=0)其中各值可以根据英文含义进行理解 :tm_year 年份(range[1,12]),tm_mon 月份(range[1,12]),tm_mday 天数(range[1,31]),tm_hour 天数(range[0,23]),tm_min 分钟 (range[0,59]), tm_sec 秒数 (range[0,61]), tm_wday 星期 (range[0,6],0 是星期日), tm_yday 一年中的一天(range[1,366] ),tm_isdst 在夏令时生效时设置为 1,而在夏令时不生效时设置为 0,值-1 表示这是未知的。
解析和格式化时间
strptime() 和 strftime() 函数可以使时间值在 struct_time 表示和字符串表示之间相互转换。
对于 strftime 函数,其中的参数参考官方即可。
x = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print(x)
这里的学习,没有什么难度大的点,孰能生巧的知识。
strptime 函数的应用
♾️ python 代码:x = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print(x)
# 方向操作,字符串格式化成 time.struct_time
struct_time = time.strptime(x, "%Y-%m-%d %H:%M:%S")
print(struct_time)需要记忆的就是 strftime 与 strptime 函数只有中间的字符不同,一个是 f ,另一个是 p。
time 小节
对于 time 模块,sleep 函数属于必备知识点,但是太常用了,你肯定已经很熟悉了。
对于模块的学习,最权威的就是官方手册了,time 模块
datetime 模块
该模块比 time 模块高级了很多,并且对 time 模块进行了封装,提供的功能更加强大了。
在 datetime 模块中,Python 提供了 5 个主要的对象类,分别如下:
datetime:允许同时操作时间和日期;date:只操作日期;time:只操作时间;timedelta:用于操作日期以及测量时间跨度;tzinfo:处理时区。
date 类
优先展示部分该类的属性和方法,都是记忆层面的知识。
min、max:date 对象能表示的最大、最小日期;resolution:date 对象表示日期的最小单位,返回天;today():返回表示当前本地日期的 date 对象;fromtimestamp(timestamp):根据时间戳,返回一个 date 对象。
测试代码如下:
♾️ python 代码:from datetime import date
import time
print('date.min:', date.min)
print('date.max:', date.max)
print('date.resolution:', date.resolution)
print('date.today():', date.today())
print('date.fromtimestamp():', date.fromtimestamp(time.time()))输出结果:
♾️ bash 代码:date.min: 0001-01-01
date.max: 9999-12-31
date.resolution: 1 day, 0:00:00
date.today(): 2021-03-09
date.fromtimestamp(): 2021-03-09date 对象的属性和方法
通过下述代码创建一个 date 对象:
♾️ python 代码:d = date(year=2021,month=3,day=9)
print(d)该对象具备下述属性和方法:
d.year:返回年;d.month:返回月;d.day:返回日;d.weekday():返回 weekday,如果是星期一,返回 0;如果是星期 2,返回 1,以此类推;d.isoweekday():返回 weekday,如果是星期一,返回 1;如果是星期 2,返回 2,以此类推;d.isocalendar():返回格式如(year, wk num, wk day);d.isoformat():返回格式如’YYYY-MM-DD’的字符串;d.strftime(fmt):自定义格式化字符串,与 time 模块中的 strftime 类似。
time 类
time 类定义的类属性:
min、max:time 类所能表示的最小、最大时间。其中,time.min = time(0, 0, 0, 0), time.max = time(23, 59, 59, 999999);- resolution:时间的最小单位,这里是 1 微秒;
通过其构造函数可以创建一个 time 对象。
t = time(hour=20, minute=20, second=40)
print(t)time 类提供的实例方法和属性:
t.hour、t.minute、t.second、t.microsecond:时、分、秒、微秒;t.tzinfo:时区信息;t.isoformat():返回型如”HH:MM:SS”格式的字符串时间表示;t.strftime(fmt):返回自定义格式化字符串。
datetime 类
该类是 date 类与 time 类的结合体,很多属性和方法前文已经介绍,再补充一些比较常用的属性和方法。
获取当前的日期与时间:
♾️ python 代码:from datetime import datetime
dt = datetime.now()
print(dt)获取时间戳:
♾️ python 代码:dt = datetime.now()
# 使用 datetime 的内置函数 timestamp()
stamp = datetime.timestamp(dt)
print(stamp)timedelta 类
通过 timedelta 函数返回一个 timedelta 时间间隔对象,该函数没有必填参数,如果写入一个整数就是间隔多少天的的意思。
# 间隔 10 天
timedelta(10)
# 跨度为1 周
timedelta(weeks=1)两个时间间隔对象可以彼此之间相加或相减,返回的仍是一个时间间隔对象。
一个 datetime 对象如果减去一个时间间隔对象,那么返回的对应减去之后的 datetime 对象,然后两个 datetime 对象如果相减,返回的是一个时间间隔对象。
更多关于 datetime 类使用的知识,可以参考 官方手册。
calendar 模块(日历)
此模块的函数都是日历相关的,例如打印某月的字符月历。
calendar 模块定义了 Calendar 类,它封装了值的计算, 例如给定月份或年份中周的日期。通过 TextCalendar 和 HTMLCalendar 类可以生成预格式化的输出。
基本代码:
♾️ python 代码:import calendar
c = calendar.TextCalendar(calendar.SUNDAY)
c.prmonth(2021, 3)上述代码,默认是从周日开始的,输出结果:
♾️ bash 代码: March 2021
Su Mo Tu We Th Fr Sa
1 2 3 4 5 6
7 8 9 10 11 12 13
14 15 16 17 18 19 20
21 22 23 24 25 26 27
28 29 30 31该模块使用频率较低,详细使用参考地址 进行学习。
Python 之 lambda 表达式
lambda 表达式基本使用
lambda 表达式也叫做匿名函数,在定义它的时候,没有具体的名称,一般用来快速定义单行函数,直接看一下基本的使用:
♾️ python 代码:fun = lambda x:x+1
print(fun(1))查看上面的代码就会发现,使用 lambda 表达式定义了一行函数,没有函数名,后面是是函数的功能,对 x 进行 +1 操作。
稍微整理一下语法格式:
lambda [参数列表]:表达式
# 英文语法格式
lambda [arg1[,arg2,arg3....argN]]:expression语法格式中有一些注意事项:
- lambda 表达式必须使用 lambda 关键字定义;
- lambda 关键字后面,冒号前面是参数列表,参数数量可以从 0 到任意。多个参数用逗号分隔,冒号右边是 lambda 表达式的返回值。
本文开始的代码,如果你希望进行改写成一般函数形式,对应如下:
♾️ python 代码:fun = lambda x:x+1
# 改写为函数形式如下:
def fun(x):return x+1当然,如果你决定上述 fun 也多余,匿名函数就不该出现这些多余的内容,你也可以写成下面这个样子,不过代码的可读性就变低了。
print((lambda x:x+1)(1))lambda 表达式一般用于无需多次使用的函数,并且该函数使用完毕就释放了所占用的空间。
lambda 表达式与 def 定义函数的区别
第一点:一个有函数名,一个没有函数名
第二点:lambda 表达式 : 后面,只能有一个表达式,多个会出现错误,也就是下面的代码是不会出现的。
# 都是错误的
lambda x:x+1 x+2由于这个原因的存在,很多人也会把 lambda 表达式称为单表达式函数。
第三点:for 语句不能用在 lambda 中
有的地方写成了 if 语句和 print 语句不能应用在 lambda 表达式中,该描述不准确,例如 下述代码就是正确的。
lambda a: 1 if a > 10 else 0基本结论就是:lambda 表达式只允许包含一个表达式,不能包含复杂语句,该表达式的运算结果就是函数的返回值。
第四点:lambda 表达式不能共享给别的程序调用
第五点:lambda 表达式能作为其它数据类型的值
例如下述代码,用 lambda 表达式是没有问题的。
my_list = [lambda a: a**2, lambda b: b**2]
fun = my_list[0]
print(fun(2))lambda 表达式应用场景
在具体的编码场景中,lambda 表达式常见的应用如下:
1. 将 lambda 表达式赋值给一个变量,然后调用这个变量
上文涉及的写法多是该用法。
fun = lambda a: a**2
print(fun(2))2. 将 lambda 表达赋值给其它函数,从而替换其它函数功能
一般这种情况是为了屏蔽某些功能,例如,可以屏蔽内置 sorted 函数。
sorted = lambda *args:None
x = sorted([3,2,1])
print(x)3. 将 lambda 表达式作为参数传递给其它函数
在某些函数中,函数设置中是可以接受匿名函数的,例如下述排序代码:
my_list = [(1, 2), (3, 1), (4, 0), (11, 4)]
my_list.sort(key=lambda x: x[1])
print(my_list)my_list 变量调用 sort 函数,参数 key 赋值了一个 lambda 表达式,该式子表示依据列表中每个元素的第二项进行排序。
4. 将 lambda 表达式应用在 filter、map、reduce 高阶函数中
这个地方先挖下一个小坑,后续讲解 filter、map、reduce 相应内容的时候,我们进行补充。
5. 将 lambda 表达式应用在函数的返回值里面
这种技巧导致的结论就是函数的返回值也是一个函数,具体测试代码如下:
def fun(n):
return lambda x:x+n
new_fun = fun(2)
print(new_fun)
# 输出内容:<function fun.<locals>.<lambda> at 0x00000000028A42F0>上述代码中,lambda 表达式实际是定义在某个函数内部的函数,称之为嵌套函数,或者内部函数。
对应的将包含嵌套函数的函数称之为外部函数。内部函数能够访问外部函数的局部变量,这个特性是闭包(Closure)编程的基础,Python第二轮也会有专门的一篇博客去介绍闭包编程相关知识。
不要滥用 lambda
lambda 表达式虽然有一些有点,但是不应过度使用 lambda,最新的官方 Python 风格指南 PEP8 建议永远不要编写下述代码:
♾️ python 代码:normalize_case = lambda s: s.casefold()因此你想创建一个函数并存储到变量中, 请使用 def 来定义。
不必要的封装
我们实现一个列表排序,按照绝对值大小进行。
my_list = [-1,2,0,-3,1,1,2,5]
sorted_list = sorted(my_list, key=lambda n: abs(n))
print(sorted_list)上述貌似用到了 lambda 表达式,但是确忘记了,在 Python 中所有的函数都可以当做参数传递。
♾️ python 代码:my_list = [-1,2,0,-3,1,1,2,5]
sorted_list = sorted(my_list, key=abs)
print(sorted_list)也就是当我们有一个满足要求的函数的时候,没有必要在额外的去使用 lambda 表达式了。
更多的内容,酒笙也发现了一篇不错的博客,你可以专门的去阅读学习一下:参考地址
lambda 表达式并不会带来程序运行效率的提高,只会使代码更简洁。
lambda 表达式是为了减少单行函数的定义而存在的。
Python 之内置函数:filter、map、reduce、zip、enumerate
filter、map、reduce、zip、enumerate
这几个函数在 Python 里面被称为高阶函数,本文主要学习它们的用法。
filter
filter 函数原型如下:
♾️ python 代码:filter(function or None, iterable) --> filter object第一个参数是判断函数(返回结果需要是 True 或者 False),第二个为序列,该函数将对 iterable 序列依次执行 function(item) 操作,返回结果是过滤之后结果组成的序列。
简单记忆:对序列中的元素进行筛选,获取符合条件的序列。
my_list = [1, 2, 3]
my_new_list = filter(lambda x: x > 2, my_list)
print(my_new_list)返回结果为:<filter object at 0x0000000001DC4F98>,使用 list 函数可以输入序列内容。
map
map 函数原型如下:
♾️ python 代码:map(func, *iterables) --> map object该函数运行之后生成一个 list,第一个参数是函数、第二个参数是一个或多个序列;
下述代码是一个简单的测试案例:
my_list = [-1,2,-3]
my_new_list = map(abs,my_list)
print(my_new_list)上述代码运行完毕,得到的结果是:<map object at 0x0000000002860390>。使用 print(list(my_new_list)) 可以得到结果。
map 函数的第一个参数,可以有多个参数,当这种情况出现后,后面的第二个参数需要是多个序列。
def fun(x, y):
return x+y
# fun 函数有2个参数,故需要两个序列
my_new_list = map(fun, [1, 2, 3], [4, 4, 4])
print(my_new_list)
print(list(my_new_list))map 函数解决的问题:
- 使用
map函数,不需要创建一个空列表; - 调用函数的时候,不需要带括号了,
map函数会自动调用目标函数; map函数会自动匹配序列中的所有元素。
reduce
reduce 函数原型如下:
♾️ python 代码:reduce(function, sequence[, initial]) -> value第一个参数是函数,第二个参数是序列,返回计算结果之后的值。该函数价值在于滚动计算应用于列表中的连续值。
测试代码如下:
from functools import reduce
my_list = [1, 2, 3]
def add(x, y):
return x+y
my_new_list = reduce(add, my_list)
print(my_list)
print(my_new_list)最终的结果是 6,如果设置第三个参数为 4,可以运行代码查看结果,最后得到的结论是,第三个参数表示初始值,即累加操作初始的数值。
♾️ python 代码:my_new_list = reduce(add, my_list,4)
print(my_list)
print(my_new_list)简单记忆:对序列内所有元素进行累计操作。
zip
zip 函数原型如下:
♾️ python 代码:zip(iter1 [,iter2 [...]]) --> zip objectzip 函数将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一样,则返回列表长度与最短的对象相同,利用星号(*)操作符,可以将元组解压为列表。
测试代码如下:
my_list1 = [1,2,3]
my_list2 = ["a","b","c"]
print(zip(my_list1,my_list2))
print(list(zip(my_list1,my_list2)))展示如何利用 * 操作符:
my_list = [(1, 'a'), (2, 'b'), (3, 'c')]
print(zip(*my_list))
print(list(zip(*my_list)))输出结果如下:
♾️ bash 代码:<zip object at 0x0000000002844788>
[(1, 2, 3), ('a', 'b', 'c')]简单记忆:zip 的功能是映射多个容器的相似索引,可以方便用于来构造字典。
enumerate
enumerate 函数原型如下:
♾️ python 代码:enumerate(iterable, start=0)参数说明:
sequence:一个序列、迭代器或其他支持迭代对象;start:下标起始位置。
该函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
测试代码如下:
weekdays = ['Mon', 'Tus', 'Wen', 'Thir']
print(enumerate(weekdays))
print(list(enumerate(weekdays)))返回结果为:<enumerate object at 0x0000000002803AB0>。
Python 之闭包操作
闭包的知识点
闭包,又叫做闭包函数、闭合函数,写法类似函数嵌套。
闭包的基本操作
从复杂的概念中抽离出来,在 Python 中,闭包就是你调用一个函数 X,这个函数返回一个 Y 函数给你,这个返回的函数 Y 就是闭包。
掌握任何技术前,都要先看一下最基本的案例代码:
♾️ python 代码:def func(parmas):
# 内部函数
def inner_func(p):
print(f"外部函数参数{parmas},内部函数参数{p}")
return inner_func
inner = func("外")
inner("内")对上述代码的说明如下,在调用 func("外") 的时候产生了一个闭包 inner_func 函数,该闭包函数内调用了外部函数 func 的参数 parmas,此时的 parmas 参数被称为自由变量(概念性名词,了解即可)。当函数 func 的声明周期结束后,parmas 这个变量依然存在,原因就是被闭包函数 inner_func 调用了,所以不会被回收。
再次对上文代码进行注释,帮助你理解闭包函数的实现。
♾️ python 代码:# 定义外部(外层)函数
def func(parmas):
# 定义内部(内层)函数
def inner_func(p):
print(f"外部函数参数{parmas},内部函数参数{p}")
# 一定要返回内层函数
return inner_func
# 调用外层函数,赋值给一个新变量 inner,此时的 inner 相当于内层函数,并且保留了自由变量 params
inner = func("外")
inner("内")总结下来,实现一个闭包需要以下几步:
- 必须有一个内层函数 ;
- 内层函数必须使用外层函数的变量,不使用外层函数的变量,闭包毫无意义;
- 外层函数的返回值必须是内层函数。
闭包作用域
先看代码:
♾️ python 代码:def outer_func():
my_list = []
def inner_func(x):
my_list.append(len(my_list)+1)
print(f"✅-my_list:{my_list}")
return inner_func
test1 = outer_func()
test1("i1")
test1("i1")
test1("i1")
test1("i1")
test2 = outer_func()
test2("i2")
test2("i2")
test2("i2")
test2("i2")上述代码中的自由变量 my_list 的作用域,只跟每次调用外层函数,生成的变量有关,闭包每个实例引用的变量互相不存在干扰。
闭包的作用
再上文中,你是否已经对闭包的作用有初步了解了?
接下来再强调一下,闭包操作中会涉及作用域相关问题,最终实现的目标是脱离了函数本身的作用范围,局部变量还可以被访问到。
def outer_func():
msg = "梦想酒笙"
def inner_func():
print(msg)
return inner_func
outer = outer_func()
outer()如果你对滚雪球第一遍还有印象,会了解到局部变量仅在函数的执行期间可用,也就说 outer_func 函数执行过之后,msg 变量就不可用了,但是上面执行了 outer_func 之后,再调用 outer 的时候,msg 变量也被输出了,这就是闭包的作用,闭包实现了局部变量可以在函数外部访问。
相应的理论再扩展一下,就是在该种情况下可以把局部变量当做全局变量用。
最后再备注一句,说明一下闭包的作用吧:闭包,保存了一些非全局变量,即保存局部信息不被销毁。
判断闭包函数
通过 函数名.__closure__ 判断一个函数是否是闭包函数。
def outer_func():
msg = "梦想酒笙"
def inner_func():
print(msg)
return inner_func
outer = outer_func()
outer()
print(outer.__closure__)(<cell at 0x0000000002806D68: str object at 0x0000000001D46718>,)返回的元组中,第一项是 CELL 即为闭包函数。
闭包存在的问题
这个问题是地址和值的问题,是操作系统底层原理导致的问题,具体实现先看代码,一个非常经典的案例。
♾️ python 代码:def count():
fs = []
for i in range(1, 4):
def f():
return i
fs.append(f)
return fs
f1, f2, f3 = count()
print(f1())
print(f2())
print(f3())上述代码不是简单的返回了一个闭包函数,而是返回的一个包含三个闭包函数的序列 list。
运行代码,输出 3 个 3,学过引用和值相关知识同学会比较容易掌握,上述代码中的 i 指向的是一个地址,而不是具体的值,这就导致当循环结束之后,i 指向那个地址的值等于 3。
本案例你记住下面这句话也可。
尽量避免在闭包中引用循环变量,或者后续会发生变化的变量。
Python 之装饰器
函数装饰器
装饰器(Decorators)在 Python 中,主要作用是修改函数的功能,而且修改前提是不变动原函数代码,装饰器会返回一个函数对象,所以有的地方会把装饰器叫做 “函数的函数”。
还存在一种设计模式叫做 “装饰器模式”,这个后续的课程会有所涉及。
装饰器调用的时候,使用 @,它是 Python 提供的一种编程语法糖,使用了之后会让你的代码看起来更加 Pythonic。
装饰器基本使用
在学习装饰器的时候,最常见的一个案例,就是统计某个函数的运行时间,接下来就为你分享一下。
计算函数运行时间:
import time
def fun():
i = 0
while i < 1000:
i += 1
def fun1():
i = 0
while i < 10000:
i += 1
s_time = time.perf_counter()
fun()
e_time = time.perf_counter()
print(f"函数{fun.__name__}运行时间是:{e_time-s_time}")如果你希望给每个函授都加上调用时间,那工作量是巨大的,你需要重复的修改函数内部代码,或者修改函数调用位置的代码。在这种需求下,装饰器语法出现了。
先看一下第一种修改方法,这种方法没有增加装饰器,但是编写了一个通用的函数,利用 Python 中函数可以作为参数这一特性,完成了代码的可复用性。
♾️ python 代码:import time
def fun():
i = 0
while i < 1000:
i += 1
def fun1():
i = 0
while i < 10000:
i += 1
def go(fun):
s_time = time.perf_counter()
fun()
e_time = time.perf_counter()
print(f"函数{fun.__name__}运行时间是:{e_time-s_time}")
if __name__ == "__main__":
go(fun1)接下来这种技巧扩展到 Python 中的装饰器语法,具体修改如下:
♾️ python 代码:import time
def go(func):
# 这里的 wrapper 函数名可以为任意名称
def wrapper():
s_time = time.perf_counter()
func()
e_time = time.perf_counter()
print(f"函数{func.__name__}运行时间是:{e_time-s_time}")
return wrapper
@go
def func():
i = 0
while i < 1000:
i += 1
@go
def func1():
i = 0
while i < 10000:
i += 1
if __name__ == '__main__':
func()在上述代码中,注意看 go 函数部分,它的参数 func 是一个函数,返回值是一个内部函数,执行代码之后相当于给原函数注入了计算时间的代码。在代码调用部分,你没有做任何修改,函数 func 就具备了更多的功能(计算运行时间的功能)。
装饰器函数成功拓展了原函数的功能,又不需要修改原函数代码,这个案例学会之后,你就已经初步了解了装饰器。
对带参数的函数进行装饰
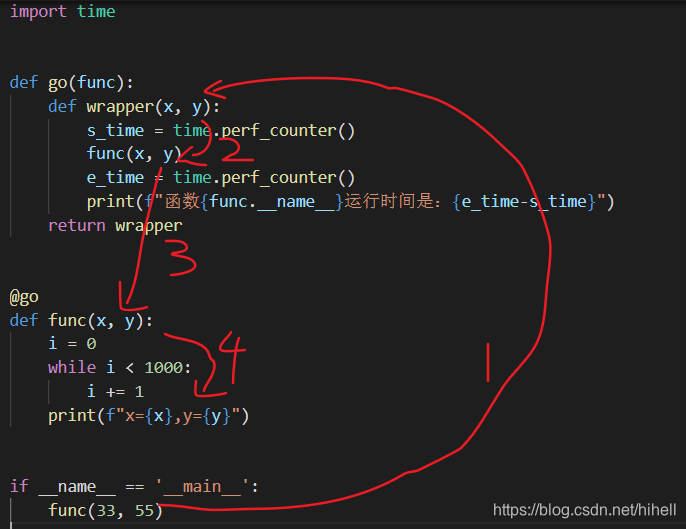
直接看代码,了解如何对带参数的函数进行装饰:
♾️ python 代码:import time
def go(func):
def wrapper(x, y):
s_time = time.perf_counter()
func(x, y)
e_time = time.perf_counter()
print(f"函数{func.__name__}运行时间是:{e_time-s_time}")
return wrapper
@go
def func(x, y):
i = 0
while i < 1000:
i += 1
print(f"x=✅,y={y}")
if __name__ == '__main__':
func(33, 55)如果你看着晕乎了,我给你标记一下参数的重点传递过程。
还有一种情况是装饰器本身带有参数,例如下述代码:
def log(text):
def decorator(func):
def wrapper(x):
print('%s %s():' % (text, func.__name__))
func(x)
return wrapper
return decorator
@log('执行')
def my_fun(x):
print(f"我是 my_fun 函数,我的参数 ✅")
my_fun(123)上述代码在编写装饰器函数的时候,在装饰器函数外层又嵌套了一层函数,最终代码的运行顺序如下所示:
♾️ python 代码:my_fun = log('执行')(my_fun)此时如果我们总结一下,就能得到结论了:使用带有参数的装饰器,是在装饰器外面又包裹了一个函数,使用该函数接收参数,并且返回一个装饰器函数。
还有一点要注意的是装饰器只能接收一个参数,而且必须是函数类型。 
多个装饰器
先临摹一下下述代码,再进行学习与研究。
♾️ python 代码:import time
def go(func):
def wrapper(x, y):
s_time = time.perf_counter()
func(x, y)
e_time = time.perf_counter()
print(f"函数{func.__name__}运行时间是:{e_time-s_time}")
return wrapper
def gogo(func):
def wrapper(x, y):
print("我是第二个装饰器")
return wrapper
@go
@gogo
def func(x, y):
i = 0
while i < 1000:
i += 1
print(f"x=✅,y={y}")
if __name__ == '__main__':
func(33, 55)代码运行之后,输出结果为:
♾️ bash 代码:我是第二个装饰器
函数wrapper运行时间是:0.0034401339999999975虽说多个装饰器使用起来非常简单,但是问题也出现了,print(f"x=✅,y={y}") 这段代码运行结果丢失了,这里就涉及多个装饰器执行顺序问题了。
先解释一下装饰器的装饰顺序。
♾️ python 代码:import time
def d1(func):
def wrapper1():
print("装饰器1开始装饰")
func()
print("装饰器1结束装饰")
return wrapper1
def d2(func):
def wrapper2():
print("装饰器2开始装饰")
func()
print("装饰器2结束装饰")
return wrapper2
@d1
@d2
def func():
print("被装饰的函数")
if __name__ == '__main__':
func()上述代码运行的结果为:
♾️ bash 代码:装饰器1开始装饰
装饰器2开始装饰
被装饰的函数
装饰器2结束装饰
装饰器1结束装饰可以看到非常对称的输出,同时证明被装饰的函数在最内层,转换成函数调用的代码如下:
♾️ python 代码:d1(d2(func))你在这部分需要注意的是,装饰器的外函数和内函数之间的语句,是没有装饰到目标函数上的,而是在装载装饰器时的附加操作。
在对函数进行装饰的时候,外函数与内函数之间的代码会被运行。
测试效果如下:
♾️ python 代码:import time
def d1(func):
print("我是 d1 内外函数之间的代码")
def wrapper1():
print("装饰器1开始装饰")
func()
print("装饰器1结束装饰")
return wrapper1
def d2(func):
print("我是 d2 内外函数之间的代码")
def wrapper2():
print("装饰器2开始装饰")
func()
print("装饰器2结束装饰")
return wrapper2
@d1
@d2
def func():
print("被装饰的函数")运行之后,你就能发现输出结果如下:
♾️ bash 代码:我是 d2 内外函数之间的代码
我是 d1 内外函数之间的代码d2 函数早于 d1 函数运行。
接下来在回顾一下装饰器的概念:
被装饰的函数的名字会被当作参数传递给装饰函数。
装饰函数执行它自己内部的代码后,会将它的返回值赋值给被装饰的函数。
这样看上文中的代码运行过程是这样的,d1(d2(func)) 执行 d2(func) 之后,原来的 func 这个函数名会指向 wrapper2 函数,执行 d1(wrapper2) 函数之后,wrapper2 这个函数名又会指向 wrapper1。因此最后的 func 被调用的时候,相当于代码已经切换成如下内容了。
# 第一步
def wrapper2():
print("装饰器2开始装饰")
print("被装饰的函数")
print("装饰器2结束装饰")
# 第二步
print("装饰器1开始装饰")
wrapper2()
print("装饰器1结束装饰")
# 第三步
def wrapper1():
print("装饰器1开始装饰")
print("装饰器2开始装饰")
print("被装饰的函数")
print("装饰器2结束装饰")
print("装饰器1结束装饰")上述第三步运行之后的代码,恰好与我们的代码输出一致。
那现在再回到本小节一开始的案例,为何输出数据丢失掉了。
♾️ python 代码:import time
def go(func):
def wrapper(x, y):
s_time = time.perf_counter()
func(x, y)
e_time = time.perf_counter()
print(f"函数{func.__name__}运行时间是:{e_time-s_time}")
return wrapper
def gogo(func):
def wrapper(x, y):
print("我是第二个装饰器")
return wrapper
@go
@gogo
def func(x, y):
i = 0
while i < 1000:
i += 1
print(f"x=✅,y={y}")
if __name__ == '__main__':
func(33, 55)在执行装饰器代码装饰之后,调用 func(33,55) 已经切换为 go(gogo(func)),运行 gogo(func) 代码转换为下述内容:
def wrapper(x, y):
print("我是第二个装饰器")在运行 go(wrapper),代码转换为:
s_time = time.perf_counter()
print("我是第二个装饰器")
e_time = time.perf_counter()
print(f"函数{func.__name__}运行时间是:{e_time-s_time}")此时,你会发现参数在运行过程被丢掉了。
functools.wraps
使用装饰器可以大幅度提高代码的复用性,但是缺点就是原函数的元信息丢失了,比如函数的 __doc__、__name__:
# 装饰器
def logged(func):
def logging(*args, **kwargs):
print(func.__name__)
print(func.__doc__)
func(*args, **kwargs)
return logging
# 函数
@logged
def f(x):
"""函数文档,说明"""
return x * x
print(f.__name__) # 输出 logging
print(f.__doc__) # 输出 None解决办法非常简单,导入 from functools import wraps ,修改代码为下述内容:
from functools import wraps
# 装饰器
def logged(func):
@wraps(func)
def logging(*args, **kwargs):
print(func.__name__)
print(func.__doc__)
func(*args, **kwargs)
return logging
# 函数
@logged
def f(x):
"""函数文档,说明"""
return x * x
print(f.__name__) # 输出 f
print(f.__doc__) # 输出 函数文档,说明基于类的装饰器
在实际编码中 一般 “函数装饰器” 最为常见,“类装饰器” 出现的频率要少很多。
基于类的装饰器与基于函数的基本用法一致,先看一段代码:
♾️ python 代码:class H1(object):
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
return '<h1>' + self.func(*args, **kwargs) + '</h1>'
@H1
def text(name):
return f'text {name}'
s = text('class')
print(s)类 H1 有两个方法:
__init__:接收一个函数作为参数,就是待被装饰的函数;__call__:让类对象可以调用,类似函数调用,触发点是被装饰的函数调用时触发。
最后在附录一篇写的不错的 博客,可以去学习。
在这里类装饰器的细节就不在展开了,等到后面滚雪球相关项目实操环节再说。
装饰器为类和类的装饰器在细节上是不同的,上文提及的是装饰器为类,你可以在思考一下如何给类添加装饰器。
内置装饰器
常见的内置装饰器有 @property、@staticmethod、@classmethod。该部分内容在细化面向对象部分进行说明,本文只做简单的备注。
@property
把类内方法当成属性来使用,必须要有返回值,相当于 getter,如果没有定义 @func.setter 修饰方法,是只读属性。
@staticmethod
静态方法,不需要表示自身对象的 self 和自身类的 cls 参数,就跟使用函数一样。
@classmethod
类方法,不需要 self 参数,但第一个参数需要是表示自身类的 cls 参数。
Python里面的字符串知识补充
Python 中最高频被使用的一个数据类型,就是字符串,本篇博客不在讨论字符串的基本使用,哪些在第一遍滚雪球的时候就已经被强调了,这次在增加 2 个细节的知识点
字符串是不可变的
字符串是不可变的,对此有一个疑问是下述代码,貌似字符串变量 my_str 发生了改变,但是你可以修改代码,获取一下代码的内存地址,会发现下述代码,其实是新创建了一个同名的字符串。
my_str = "hello "
my_str += "world"
print(my_str)比较内存地址。
♾️ python 代码:my_str = "hello "
print(id(my_str))
my_str += "world"
print(id(my_str))
print(my_str)运行结果如下:
♾️ bash 代码:30801624
42418864
hello world字符串拼接效率问题
对比下述几段代码比较字符串拼接的效率问题。
♾️ python 代码:import time
# += 写法
def m0():
s = ' '
for n in range(0, 100000):
s += str(n)
# join 写法
def m1():
l = []
for n in range(0, 100000):
l.append(str(n))
s = ' '.join(l)
# pythonic 写法
def m2():
s = ' '.join(map(str, range(0, 100000)))
start_time = time.perf_counter()
m0()
end_time = time.perf_counter()
print("代码运行时间为:", end_time-start_time)在循环 100000 次的情况下,前 2 份代码消耗时间差异不大,但是 m2 效率高了一些,随着循环次数增大,会发现 m2 逐渐拉开差距,甚至数据到一千万的时候,m0 没有计算出结果,因为电脑原因,卡住了。
- m0:代码运行时间为: 0.026987474000000004
- m1:代码运行时间为: 0.025112976000000002
- m2:代码运行时间为: 0.019118731
从字符串这种数据类型本身出发,join 函数比 += 快,最后一种写法,其实是 map 遍历提高的效率,这点需要注意下,不过第三种写法确实比较 pythonic。